
This post is inspired by the original paper Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learningk and the accompanying blog postk.
Introduction
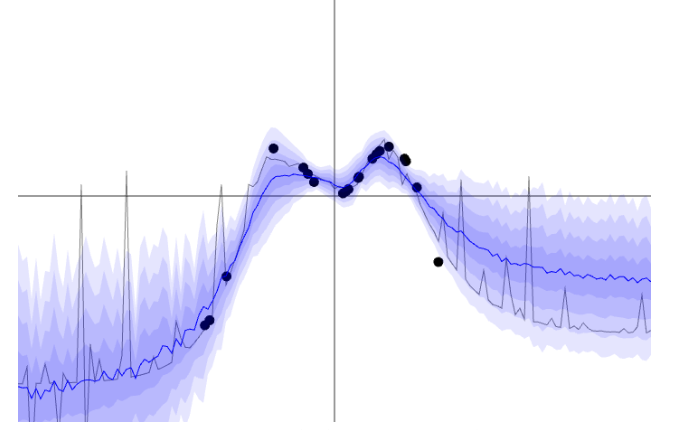
Dropout Sampling is a simple yet very powerful technique that works well when deploying deep learning models for critical applications is dropout sampling which you can easily add to your models to estimate the uncertainty of predictions.
The main idea is to run inference on a single sample multiple times with dropout layers ENABLED
so after calling model.eval() you have to switch the layers to train
model.dropout_layer1.train()
This will yield multiple predictions (a distribution) for that one sample. The standard deviation of the predictions will indicate how confident your model is
Run your own experiment
Let's take this dummy dataset as an example, where the model will only be trained on range of [-3, 3].
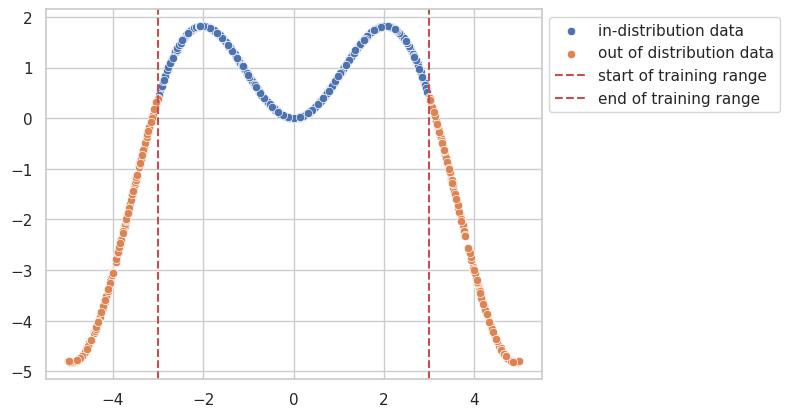
So for the data points beyond the training distribution we would like to know when the model starts to "guess" and quantify this uncertainty .. here is where dropout sampling comes into play
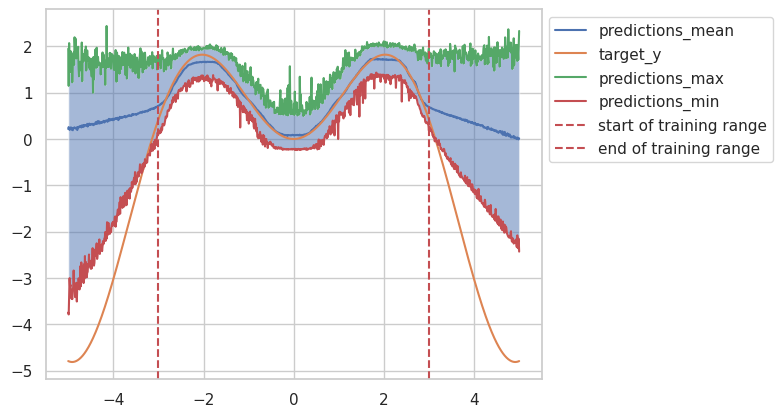
The figure below shows that the results will start to deviate from the target once we try to predict on data points beyond the range of [-3, 3]
but we can also see that standard deviation of these predictions will start to significantly vary as well
This is a vectorized implementation to avoid creating for loops, simply repeat the input along the batch dimension n times
Dropout Sampling Implementation
def predict_with_uncertainty(model, input_tensor, num_samples=100): "Apply dropout sampling for an input sample" model.eval() model.dropout_layer1.train() # IMPORTANT enable dropout during inference model.dropout_layer2.train() # IMPORTANT enable dropout during inference #... more dropout layers input_tensor = input_tensor.repeat(num_samples, 1, 1) with torch.no_grad(): predictions = model(input_tensor) mean_predictions = predictions.mean(dim=0) uncertainty = predictions.std(dim=0) return mean_predictions,uncertainty