
Introduction
This is a walkthrough of how to create an AI clone that is context-aware and can answer questions about your experiences, projects, skills, etc. I have used llama-indexk and Vercel AI SDKk to create it, but there are many tools out there that could achieve the same result.
The fundamental concept that powers this clone is of course an LLM but with Retrieval-Augmented Generation (RAG). RAG is the method used for generating text using additional information fetched from your own data sources, which can greatly increase the accuracy of the response and make it personal by providing it with better context.
For more information on RAG you can check out this great explanation by Coherek.
I have tested this simple RAG with multiple prompts and the answers surprisingly accurate and relevant. Here are a few examples:
- Where did I work in 2022?
- What is the tech stack I used in my last project?
- What are my top 3 skills?
- Who are the authors of the "Reuse-oriented SLAM" paper?
Embedding and Indexing the data
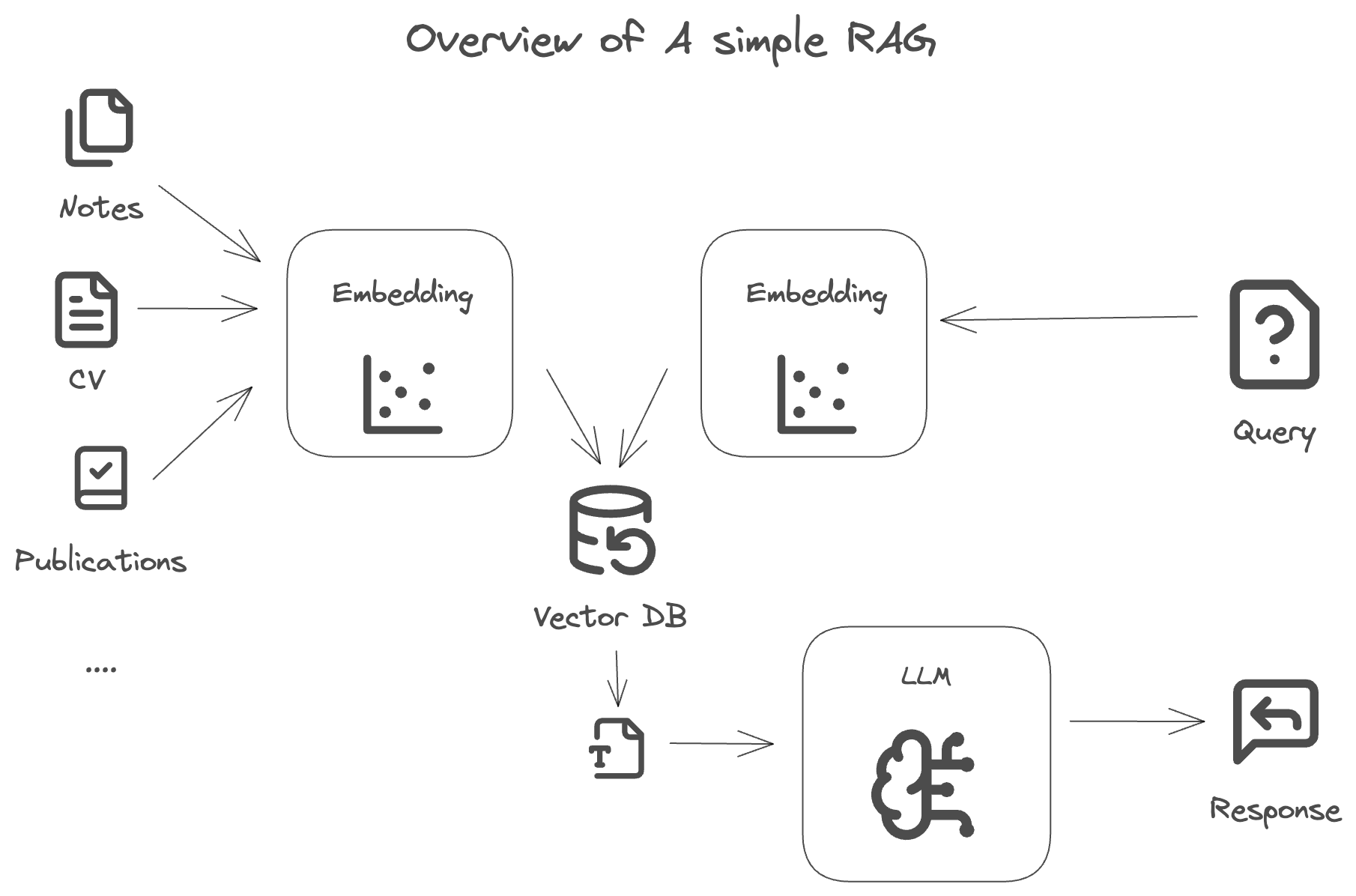
The first step is to collect the data that you would like the AI clone to be aware of. This could be your resume, projects, experiences, etc.
Once that is done, you can embed the data using llama-index. The embedding process is quite simple and can be done in a few lines of code. Note that this is done only once, and the embeddings are stored in a vector database to be used later on for querying.
The output of the embedding process is a vector that represents a chunk of text from your data in a high-dimensional space.
# Ingest documents from multiple sources import uuid from llama_index.core import Document, SimpleDirectoryReader from llama_index.readers.web import SimpleWebPageReader documents = SimpleDirectoryReader("./data").load_data() documents += [ Document( text="I am currently living in Amsterdam.", doc_id=str(uuid.uuid4()), metadata={ "category": "personal info", }, # metadata will propagate to the nodes ) ] documents += SimpleWebPageReader(html_to_text=True).load_data( urls=["https://moabdelhady.com"] )
Storing the index in a vector database
The next step is to store the index in a vector database. This is done to save time and money as the embeddings are quite large and can take a while to compute, especially if you have many publications, books, etc, that you would like the system to be able to answer questions about.
For this project, I have used pinecone.iok as the vector database, but you can use any other vector database that you are comfortable with.
import os from pinecone import Pinecone, ServerlessSpec, PodSpec from llama_index.vector_stores.pinecone import PineconeVectorStore from llama_index.core import VectorStoreIndex from llama_index.core.response.pprint_utils import pprint_source_node from llama_index.core import StorageContext from llama_index.embeddings.openai import OpenAIEmbedding pc = Pinecone( api_key=os.environ.get("PINECONE_API_KEY") ) pinecone_index = pc.Index("quickstart-index") pinecone_index.describe_index_stats() vector_store = PineconeVectorStore(pinecone_index=pinecone_index) storage_context = StorageContext.from_defaults(vector_store=vector_store) # You can try out different models for the embeddings, I have used the text-embedding-3-small model from OpenAI embed_model = OpenAIEmbedding(model="text-embedding-3-small") index = VectorStoreIndex( nodes, storage_context=storage_context, show_progress=True, embed_model=embed_model )
After this is done, you can navigate to the Pinecone dashboard and see the index that was created, along with the embeddings.
Building a query engine
This is mainly the object that will take any user query, embed it, and then search the index for the most relevant embeddings. The search is done using a similarity metric like cosine similarity, and the top results are then used as context to the LLM to generate the response.
This is how you can ask the AI very specific questions about your data, experiences, projects, etc. and get a very accurate response.
Integration with your application
To tie everything together, you can use the Vercel AI SDK to create a simple API that takes in a user query and returns the response generated.
It is helpful to take a look at create-llamak, which is a command line tool that will create all the boilerplate code for you to get started with llama-index, but these are the 2 main parts that you need to implement.
On the frontend side, you can create a simple interface to accept user input and display history of the chat.
'use client'; import { useChat } from 'ai/react'; export default function Chat() { const { messages, input, handleInputChange, handleSubmit } = useChat(); return ( <div className="flex flex-col w-full max-w-md py-24 mx-auto stretch"> <div className="space-y-4"> {messages.map(m => ( <div key={m.id} className="whitespace-pre-wrap"> <div> <div className="font-bold">{m.role}</div> <p>{m.content}</p> </div> </div> ))} </div> <form onSubmit={handleSubmit}> <input className="fixed bottom-0 w-full max-w-md p-2 mb-8 border border-gray-300 rounded shadow-xl" value={input} placeholder="Say something..." onChange={handleInputChange} /> </form> </div> ); }
Then on the backend, you need a route handler to accept the user query, pass it to the query engine, and return the response. First, you can create the query engine as follows:
export async function createChatEngine() { const serviceContext = serviceContextFromDefaults({ llm: llm, chunkSize: CHUNK_SIZE, chunkOverlap: CHUNK_OVERLAP, embedModel: embedModel, }); const pcvs = new PineconeVectorStore({ indexName: INDEX_NAME, embedModel: embedModel, }); const index = await VectorStoreIndex.fromVectorStore(pcvs, serviceContext); const retriever = index.asRetriever({ similarityTopK: 3 }); const nodePostprocessors = [ new SimilarityPostprocessor({ similarityCutoff: 0.3 }), ]; return { chatEngine: new ContextChatEngine({ chatModel: llm, nodePostprocessors: nodePostprocessors, retriever, }), retriever, }; }
Then in the route handler, you can use the chat engine to generate the response and add the custom system prompt.
const response = await chatEngine.chat({ message: userMessage.content, chatHistory: [ { role: "system", content: "You are a helpful virtual AI clone. Your answers should be concise and to the point. Check your knowledge base before answering. If no relevant information is found in the tool calls, respond, 'Sorry, I do not know.'", }, ...messages, ], stream: true, }); // Transform LlamaIndex stream to Vercel/AI format const { stream } = LlamaIndexStream(response);