
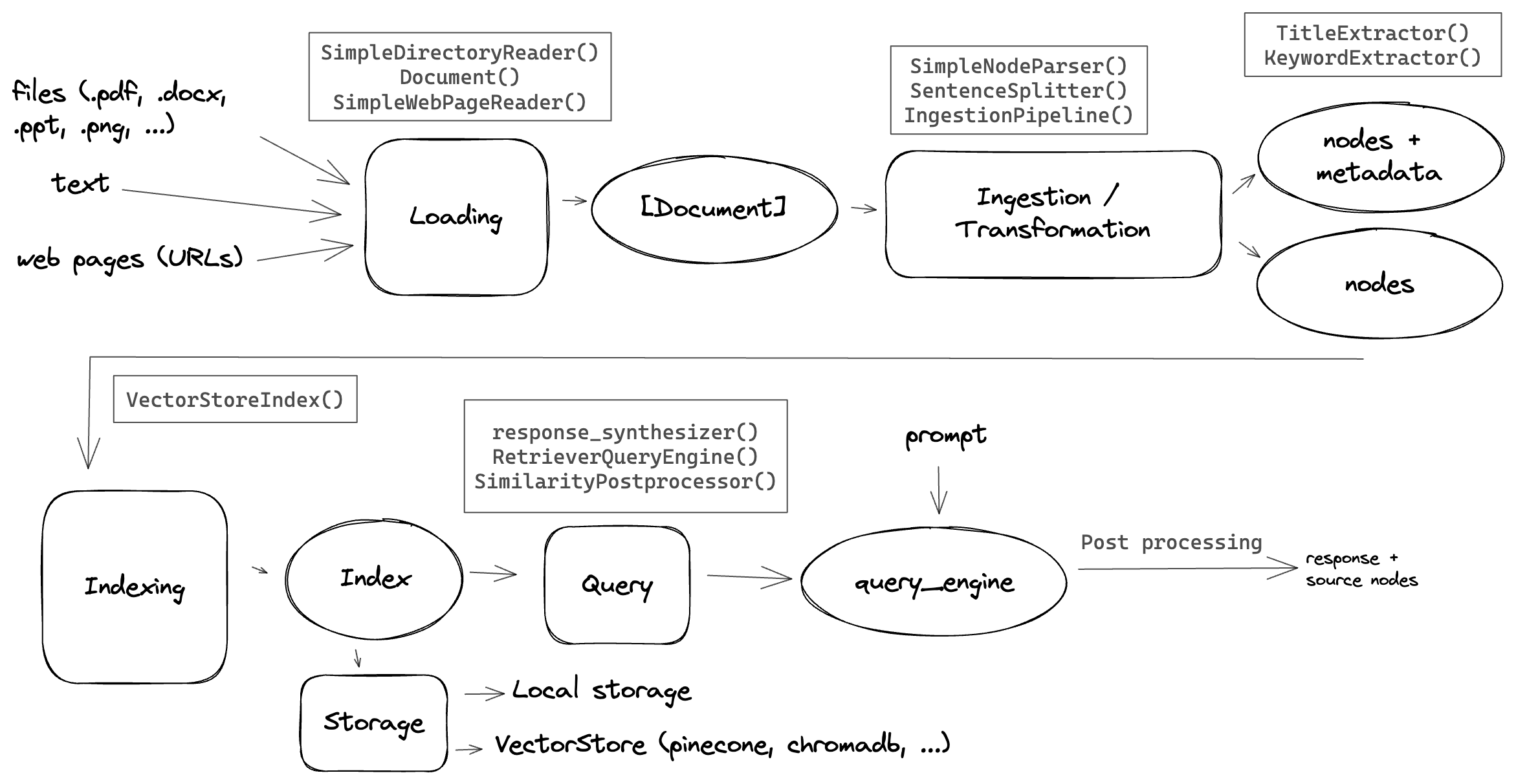
Workflow
The main workflow involved in developing such an application is:
- Loading / ingestion of the data
- Transformation / pre-processing
- Embedding the pieces of text and building an index
- Storing the index to save time and $ money
- Building a query engine along with the post processing pipeline
Loading & ingestion
This is the first stage of the pipeline, where we load all the source data that we want to include in the RAG applicaiton into llama-index Document
which is one of the main concepts that encapsulates text data along with metadata. The metadata define here also propagates to the nodes, which will be covered in the next sections.
# Ingest documents from multiple sources import uuid from llama_index.core import Document, SimpleDirectoryReader from llama_index.readers.web import SimpleWebPageReader documents = SimpleDirectoryReader("./data").load_data() documents += [ Document( text="The simplest way to store your indexed data is to use the built-in .persist() method of every Index, " "which writes all the data to disk at the location specified. This works for any type of index.", doc_id=str(uuid.uuid4()), metadata={ "foo": "bar", "category": "documentation", }, # metadata will propagate to the nodes excluded_llm_metadata_keys=[ "foo" ], # some keys could be excluded from the text_content() ) ] documents += SimpleWebPageReader(html_to_text=True).load_data( urls=["https://docs.pinecone.io/home"] )
Transformation & pre-processing
Once the documents are loaded, we can split them into chunks/nodes that express the relationship between the nodes and the parent document. Note that any metadata defined in the document will also be available in the nodes.
# Creating nodes/chunks from llama_index.core.node_parser import ( SimpleNodeParser, SentenceSplitter, TokenTextSplitter, TextSplitter, ) from llama_index.core.ingestion import IngestionPipeline # creating text nodes parser = SimpleNodeParser.from_defaults() nodes = parser.get_nodes_from_documents(documents) print(len(nodes)) # using a different splitter -> this will create different number of nodes text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20) pipeline = IngestionPipeline(transformations=[text_splitter]) nodes = pipeline.run(documents=documents) print(len(nodes))
Automatic Metadata Extraction
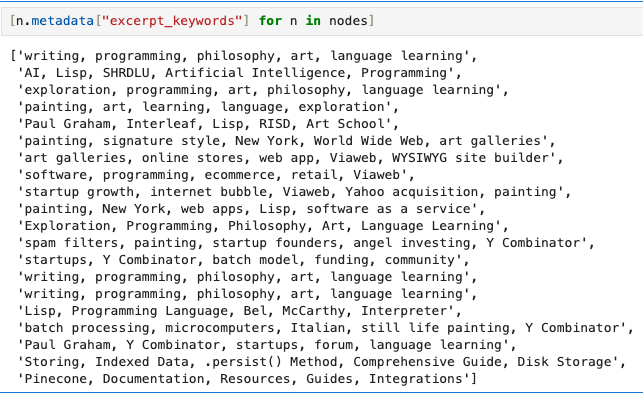
One of the very cool features, is the ability to enrich the chunks of text by their own metadata. This has been proven to drastically improve the results of the retrieval and the repsonse that we get from an LLM. llama-index has built-in metadata extractors to generate titles, keywords, etc.
# creating nodes with automatic metadata extraction # here we need to start making API requests to an LLM # you NEED to set the OPENAI_API_KEY env variable import nest_asyncio nest_asyncio.apply() from llama_index.core.extractors import TitleExtractor, KeywordExtractor from llama_index.core.schema import MetadataMode from llama_index.llms.openai import OpenAI llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1) enrich_metadata_pipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=1024, chunk_overlap=20), TitleExtractor(llm=llm, metadata_mode=MetadataMode.EMBED), KeywordExtractor(llm=llm, metadata_mode=MetadataMode.EMBED), ] ) nodes = enrich_metadata_pipeline.run(documents=documents)
This will add a keywords metadata to the nodes, that will be included later on in the embedding.
Embedding + Storage
At this point, we can create the embeddings and store them. For this usecase, I used the default embedding model provided by llama-index which is the Text-embedding-ada-002-v2
from llama_index.core import VectorStoreIndex # On a high-level, index can be created from documents directly, this will use a default node parser # index = VectorStoreIndex.from_documents(documents, show_progress=True) index = VectorStoreIndex(nodes, show_progress=True) # this will overwrite all the json files in storage index.storage_context.persist(persist_dir="./storage") from llama_index.core import StorageContext, load_index_from_storage storage_context = StorageContext.from_defaults(persist_dir="./storage") index = load_index_from_storage(storage_context)
Building a query engine
Finally we can start asking questions and checking the which nodes/documents are the most relevant.
from llama_index.core import ( VectorStoreIndex, get_response_synthesizer, StorageContext, load_index_from_storage, ) from llama_index.core.retrievers import VectorIndexRetriever from llama_index.core.query_engine import RetrieverQueryEngine from llama_index.core.postprocessor import ( SimilarityPostprocessor, KeywordNodePostprocessor, ) from llama_index.core.response_synthesizers import ResponseMode from llama_index.core.response.pprint_utils import pprint_source_node retriever = VectorIndexRetriever(index=index, similarity_top_k=5) response_synthesizer = get_response_synthesizer(response_mode=ResponseMode.COMPACT) # assemble the query engine query_engine = RetrieverQueryEngine( retriever=retriever, response_synthesizer=response_synthesizer, node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.8)], ) response = query_engine.query("Where did paul graham study?") print(response) for node in response.source_nodes: pprint_source_node(node)
Conclusion
In this guide, we have built a simple hybrid RAG application using Llama-Index. By following the steps of data loading and ingestion, transformation and pre-processing, embedding and storage, and building a query engine, you can create an application that efficiently handles and queries large sets of text data. This framework can be extended further with more sophisticated pre-processing, embedding techniques, and query strategies to handle various use cases and datasets.
Happy coding!